Phil Hands: Sleep Apnoea
 I just noticed that I wrote this a decade ago, and then never got round to posting
it, so thought I might kick it off now to mark my tentative return to blogging.
At the
I just noticed that I wrote this a decade ago, and then never got round to posting
it, so thought I might kick it off now to mark my tentative return to blogging.
At the  I just noticed that I wrote this a decade ago, and then never got round to posting
it, so thought I might kick it off now to mark my tentative return to blogging.
At the
I just noticed that I wrote this a decade ago, and then never got round to posting
it, so thought I might kick it off now to mark my tentative return to blogging.
At the
| Publisher: | W.W. Norton & Company |
| Copyright: | 2023 |
| ISBN: | 1-324-07434-5 |
| Format: | Kindle |
| Pages: | 255 |
arduino was in Debian.
But it turns out that the Debian package s version doesn t support the DigiSpark. (AFAICT from the list it offered me, I m not sure it supports any ATTiny85 board.) Also, disturbingly, its board manager seemed to be offering to install board support, suggesting it would download stuff from the internet and run it. That wouldn t be acceptable for my main laptop.
I didn t expect to be doing much programming or debugging, and the project didn t have significant security requirements: the chip, in my circuit, has only a very narrow ability do anything to the real world, and no network connection of any kind. So I thought it would be tolerable to do the project on my low-security video laptop . That s the machine where I m prepared to say yes to installing random software off the internet.
So I went to the upstream Arduino site and downloaded a tarball containing the Arduino IDE. After unpacking that in /opt it ran and produced a pointy-clicky IDE, as expected. I had already found a 3rd-party tutorial saying I needed to add a magic URL (from the DigiSpark s vendor) in the preferences. That indeed allowed it to download a whole pile of stuff. Compilers, bootloader clients, god knows what.
However, my tiny test program didn t make it to the board. Half-buried in a too-small window was an error message about the board s bootloader ( Micronucleus ) being too new.
The boards I had came pre-flashed with micronucleus 2.2. Which is hardly new, But even so the official Arduino IDE (or maybe the DigiSpark s board package?) still contains an old version. So now we have all the downsides of curl bash-ware, but we re lacking the it s up to date and it just works upsides.
Further digging found some random forum posts which suggested simply downloading a newer micronucleus and manually stuffing it into the right place: one overwrites a specific file, in the middle the heaps of stuff that the Arduino IDE s board support downloader squirrels away in your home directory. (In my case, the home directory of the untrusted shared user on the video laptop,)
So, whatever . I did that. And it worked!
Having demo d my ability to run code on the board, I set about writing my program.
Writing C again
The programming language offered via the Arduino IDE is C.
It s been a little while since I started a new thing in C. After having spent so much of the last several years writing Rust. C s primitiveness quickly started to grate, and the program couldn t easily be as DRY as I wanted (Don t Repeat Yourself, see Wilson et al, 2012, 4, p.6). But, I carried on; after all, this was going to be quite a small job.
Soon enough I had a program that looked right and compiled.
Before testing it in circuit, I wanted to do some QA. So I wrote a simulator harness that #included my Arduino source file, and provided imitations of the few Arduino library calls my program used. As an side advantage, I could build and run the simulation on my main machine, in my normal development environment (Emacs, make, etc.). The simulator runs confirmed the correct behaviour. (Perhaps there would have been some more faithful simulation tool, but the Arduino IDE didn t seem to offer it, and I wasn t inclined to go further down that kind of path.)
So I got the video laptop out, and used the Arduino IDE to flash the program. It didn t run properly. It hung almost immediately. Some very ad-hoc debugging via led-blinking (like printf debugging, only much worse) convinced me that my problem was as follows:
Arduino C has 16-bit ints. My test harness was on my 64-bit Linux machine. C was autoconverting things (when building for the micrcocontroller). The way the Arduino IDE ran the compiler didn t pass the warning options necessary to spot narrowing implicit conversions. Those warnings aren t the default in C in general javax.jmdns, with hex DNS packet dumps. WTF.
Other things that were vexing about the Arduino IDE: it has fairly fixed notions (which don t seem to be documented) about how your files and directories ought to be laid out, and magical machinery for finding things you put nearby its sketch (as it calls them) and sticking them in its ear, causing lossage. It has a tendency to become confused if you edit files under its feet (e.g. with git checkout). It wasn t really very suited to a workflow where principal development occurs elsewhere.
And, important settings such as the project s clock speed, or even the target board, or the compiler warning settings to use weren t stored in the project directory along with the actual code. I didn t look too hard, but I presume they must be in a dotfile somewhere. This is madness.
Apparently there is an Arduino CLI too. But I was already quite exasperated, and I didn t like the idea of going so far off the beaten path, when the whole point of using all this was to stay with popular tooling and share fate with others. (How do these others cope? I have no idea.)
As for the integer overflow bug:
I didn t seriously consider trying to figure out how to control in detail the C compiler options passed by the Arduino IDE. (Perhaps this is possible, but not really documented?) I did consider trying to run a cross-compiler myself from the command line, with appropriate warning options, but that would have involved providing (or stubbing, again) the Arduino/DigiSpark libraries (and bugs could easily lurk at that interface).
Instead, I thought, if only I had written the thing in Rust . But that wasn t possible, was it? Does Rust even support this board?
Rust on the DigiSpark
I did a cursory web search and found a very useful blog post by Dylan Garrett.
This encouraged me to think it might be a workable strategy. I looked at the instructions there. It seemed like I could run them via the privsep arrangement I use to protect myself when developing using upstream cargo packages from crates.io.
I got surprisingly far surprisingly quickly. It did, rather startlingly, cause my rustup to download a random recent Nightly Rust, but I have six of those already for other Reasons. Very quickly I got the trinket LED blink example, referenced by Dylan s blog post, to compile. Manually copying the file to the video laptop allowed me to run the previously-downloaded micronucleus executable and successfully run the blink example on my board!
I thought a more principled approach to the bootloader client might allow a more convenient workflow. I found the upstream Micronucleus git releases and tags, and had a look over its source code, release dates, etc. It seemed plausible, so I compiled v2.6 from source. That was a success: now I could build and install a Rust program onto my board, from the command line, on my main machine. No more pratting about with the video laptop.
I had got further, more quickly, with Rust, than with the Arduino IDE, and the outcome and workflow was superior.
So, basking in my success, I copied the directory containing the example into my own project, renamed it, and adjusted the path references.
That didn t work. Now it didn t build. Even after I copied about .cargo/config.toml and rust-toolchain.toml it didn t build, producing a variety of exciting messages, depending what precisely I tried. I don t have detailed logs of my flailing: the instructions say to build it by cd ing to the subdirectory, and, given that what I was trying to do was to not follow those instructions, it didn t seem sensible to try to prepare a proper repro so I could file a ticket. I wasn t optimistic about investigating it more deeply myself: I have some experience of fighting cargo, and it s not usually fun. Looking at some of the build control files, things seemed quite complicated.
Additionally, not all of the crates are on crates.io. I have no idea why not. So, I would need to supply local copies of them anyway. I decided to just git subtree add the avr-hal git tree.
(That seemed better than the approach taken by the avr-hal project s cargo template, since that template involve a cargo dependency on a foreign git repository. Perhaps it would be possible to turn them into path dependencies, but given that I had evidence of file-location-sensitive behaviour, which I didn t feel like I wanted to spend time investigating, using that seems like it would possibly have invited more trouble. Also, I don t like package templates very much. They re a form of clone-and-hack: you end up stuck with whatever bugs or oddities exist in the version of the template which was current when you started.)
Since I couldn t get things to build outside avr-hal, I edited the example, within avr-hal, to refer to my (one) program.rs file outside avr-hal, with a #[path] instruction. That s not pretty, but it worked.
I also had to write a nasty shell script to work around the lack of good support in my nailing-cargo privsep tool for builds where cargo must be invoked in a deep subdirectory, and/or Cargo.lock isn t where it expects, and/or the target directory containing build products is in a weird place. It also has to filter the output from cargo to adjust the pathnames in the error messages. Otherwise, running both cd A; cargo build and cd B; cargo build from a Makefile produces confusing sets of error messages, some of which contain filenames relative to A and some relative to B, making it impossible for my Emacs to reliably find the right file.
RIIR (Rewrite It In Rust)
Having got my build tooling sorted out I could go back to my actual program.
I translated the main program, and the simulator, from C to Rust, more or less line-by-line. I made the Rust version of the simulator produce the same output format as the C one. That let me check that the two programs had the same (simulated) behaviour. Which they did (after fixing a few glitches in the simulator log formatting).
Emboldened, I flashed the Rust version of my program to the DigiSpark. It worked right away!
RIIR had caused the bug to vanish. Of course, to rewrite the program in Rust, and get it to compile, it was necessary to be careful about the types of all the various integers, so that s not so surprising. Indeed, it was the point. I was then able to refactor the program to be a bit more natural and DRY, and improve some internal interfaces. Rust s greater power, compared to C, made those cleanups easier, so making them worthwhile.
However, when doing real-world testing I found a weird problem: my timings were off. Measured, the real program was too fast by a factor of slightly more than 2. A bit of searching (and searching my memory) revealed the cause: I was using a board template for an Adafruit Trinket. The Trinket has a clock speed of 8MHz. But the DigiSpark runs at 16.5MHz. (This is discussed in a ticket against one of the C/C++ libraries supporting the ATTiny85 chip.)
The Arduino IDE had offered me a choice of clock speeds. I have no idea how that dropdown menu took effect; I suspect it was adding prelude code to adjust the clock prescaler. But my attempts to mess with the CPU clock prescaler register by hand at the start of my Rust program didn t bear fruit.
So instead, I adopted a bodge: since my code has (for code structure reasons, amongst others) only one place where it dealt with the underlying hardware s notion of time, I simply changed my delay function to adjust the passed-in delay values, compensating for the wrong clock speed.
There was probably a more principled way. For example I could have (re)based my work on either of the two unmerged open MRs which added proper support for the DigiSpark board, rather than abusing the Adafruit Trinket definition. But, having a nearly-working setup, and an explanation for the behaviour, I preferred the narrower fix to reopening any cans of worms.
An offer of help
As will be obvious from this posting, I m not an expert in dev tools for embedded systems. Far from it. This area seems like quite a deep swamp, and I m probably not the person to help drain it. (Frankly, much of the improvement work ought to be done, and paid for, by hardware vendors.)
But, as a full Member of the Debian Project, I have considerable gatekeeping authority there. I also have much experience of software packaging, build systems, and release management. If anyone wants to try to improve the situation with embedded tooling in Debian, and is willing to do the actual packaging work. I would be happy to advise, and to review and sponsor your contributions.
An obvious candidate: it seems to me that micronucleus could easily be in Debian. Possibly a DigiSpark board definition could be provided to go with the arduino package.
Unfortunately, IMO Debian s Rust packaging tooling and workflows are very poor, and the first of my suggestions for improvement wasn t well received. So if you need help with improving Rust packages in Debian, please talk to the Debian Rust Team yourself.
Conclusions
Embedded programming is still rather a mess and probably always will be.
Embedded build systems can be bizarre. Documentation is scant. You re often expected to download board support packages full of mystery binaries, from the board vendor (or others).
Dev tooling is maddening, especially if aimed at novice programmers. You want version control? Hermetic tracking of your project s build and install configuration? Actually to be told by the compiler when you write obvious bugs? You re way off the beaten track.
As ever, Free Software is under-resourced and the maintainers are often busy, or (reasonably) have other things to do with their lives.
All is not lost
Rust can be a significantly better bet than C for embedded software:
The Rust compiler will catch a good proportion of programming errors, and an experienced Rust programmer can arrange (by suitable internal architecture) to catch nearly all of them. When writing for a chip in the middle of some circuit, where debugging involves staring an LED or a multimeter, that s precisely what you want.
Rust embedded dev tooling was, in this case, considerably better. Still quite chaotic and strange, and less mature, perhaps. But: significantly fewer mystery downloads, and significantly less crazy deviations from the language s normal build system. Overall, less bad software supply chain integrity.
The ATTiny85 chip, and the DigiSpark board, served my hardware needs very well. (More about the hardware aspects of this project in a future posting.) The eighth release of the still fairly new qlcal package
arrivied at CRAN today.
qlcal
delivers the calendaring parts of QuantLib. It is provided (for the R
package) as a set of included files, so the package is self-contained
and does not depend on an external QuantLib library (which can be
demanding to build). qlcal covers
over sixty country / market calendars and can compute holiday lists, its
complement (i.e. business day lists) and much more.
This release brings updates from the just-released QuantLib 1.32 version. It also
avoids a nag from R during build ( only specify C++14 if you really need
it ) but switching to a versioned depends on R 4.2.0 or later. This
implies C++14 or later as the default. If you need qlcal on an
older R, grab the sources, edit
The eighth release of the still fairly new qlcal package
arrivied at CRAN today.
qlcal
delivers the calendaring parts of QuantLib. It is provided (for the R
package) as a set of included files, so the package is self-contained
and does not depend on an external QuantLib library (which can be
demanding to build). qlcal covers
over sixty country / market calendars and can compute holiday lists, its
complement (i.e. business day lists) and much more.
This release brings updates from the just-released QuantLib 1.32 version. It also
avoids a nag from R during build ( only specify C++14 if you really need
it ) but switching to a versioned depends on R 4.2.0 or later. This
implies C++14 or later as the default. If you need qlcal on an
older R, grab the sources, edit DESCRIPTION to remove this
constraint and set the standard as before in src/Makevars
(or src/Makevars.win).
Courtesy of my CRANberries, there is a diffstat report for this release. See the project page and package documentation for more details, and more examples. If you like this or other open-source work I do, you can now sponsor me at GitHub.Changes in version 0.0.8 (2023-10-21)
- A small set of updates from QuantLib 1.32 have been applied
- The explicit C++14 compilation standard has been replaced with an implicit one by relying on R (>= 4.2.0)
This post by Dirk Eddelbuettel originated on his Thinking inside the box blog. Please report excessive re-aggregation in third-party for-profit settings.
| Series: | Fall Revolution #3 |
| Publisher: | Tor |
| Copyright: | 1998 |
| Printing: | August 2000 |
| ISBN: | 0-8125-6858-3 |
| Format: | Mass market |
| Pages: | 305 |
Life is a process of breaking down and using other matter, and if need be, other life. Therefore, life is aggression, and successful life is successful aggression. Life is the scum of matter, and people are the scum of life. There is nothing but matter, forces, space and time, which together make power. Nothing matters, except what matters to you. Might makes right, and power makes freedom. You are free to do whatever is in your power, and if you want to survive and thrive you had better do whatever is in your interests. If your interests conflict with those of others, let the others pit their power against yours, everyone for theirselves. If your interests coincide with those of others, let them work together with you, and against the rest. We are what we eat, and we eat everything. All that you really value, and the goodness and truth and beauty of life, have their roots in this apparently barren soil. This is the true knowledge. We had founded our idealism on the most nihilistic implications of science, our socialism on crass self-interest, our peace on our capacity for mutual destruction, and our liberty on determinism. We had replaced morality with convention, bravery with safety, frugality with plenty, philosophy with science, stoicism with anaesthetics and piety with immortality. The universal acid of the true knowledge had burned away a world of words, and exposed a universe of things. Things we could use.This is certainly something that some people will believe, particularly cynical college students who love political theory, feeling smarter than other people, and calling their pet theories things like "the true knowledge." It is not even remotely believable as the governing philosophy of a solar confederation. The point of government for the average person in human society is to create and enforce predictable mutual rules that one can use as a basis for planning and habits, allowing you to not think about politics all the time. People who adore thinking about politics have great difficulty understanding how important it is to everyone else to have ignorable government. Constantly testing your power against other coalitions is a sport, not a governing philosophy. Given the implication that this testing is through violence or the threat of violence, it beggars belief that any large number of people would tolerate that type of instability for an extended period of time. Ellen is fully committed to the true knowledge. MacLeod likely is not; I don't think this represents the philosophy of the author. But the primary political conflict in this novel famous for being political science fiction is between the above variation of anarchy and an anarchocapitalist society, neither of which are believable as stable political systems for large numbers of people. This is a bit like seeking out a series because you were told it was about a great clash of European monarchies and discovering it was about a fight between Liberland and Sealand. It becomes hard to take the rest of the book seriously. I do realize that one point of political science fiction is to play with strange political ideas, similar to how science fiction plays with often-implausible science ideas. But those ideas need some contact with human nature. If you're going to tell me that the key to clawing society back from a world-wide catastrophic descent into chaos is to discard literally every social system used to create predictability and order, you had better be describing aliens, because that's not how humans work. The rest of the book is better. I am untangling a lot of backstory for the above synopsis, which in the book comes in dribs and drabs, but piecing that together is good fun. The plot is far more straightforward than the previous two books in the series: there is a clear enemy, a clear goal, and Ellen goes from point A to point B in a comprehensible way with enough twists to keep it interesting. The core moral conflict of the book is that Ellen is an anti-AI fanatic to the point that she considers anyone other than non-uploaded humans to be an existential threat. MacLeod gives the reader both reasons to believe Ellen is right and reasons to believe she's wrong, which maintains an interesting moral tension. One thing that MacLeod is very good at is what Bob Shaw called "wee thinky bits." I think my favorite in this book is the computer technology used by the Cassini Division, who have spent a century in close combat with inimical AI capable of infecting any digital computer system with tailored viruses. As a result, their computers are mechanical non-Von-Neumann machines, but mechanical with all the technology of a highly-advanced 24th century civilization with nanometer-scale manufacturing technology. It's a great mental image and a lot of fun to think about. This is the only science fiction novel that I can think of that has a hard-takeoff singularity that nonetheless is successfully resisted and fought to a stand-still by unmodified humanity. Most writers who were interested in the singularity idea treated it as either a near-total transformation leaving only remnants or as something that had to be stopped before it started. MacLeod realizes that there's no reason to believe a post-singularity form of life would be either uniform in intent or free from its own baffling sudden collapses and reversals, which can be exploited by humans. It makes for a much better story. The sociology of this book is difficult to swallow, but the characterization is significantly better than the previous books of the series and the plot is much tighter. I was too annoyed by the political science to fully enjoy it, but that may be partly the fault of my expectations coming in. If you like chewy, idea-filled science fiction with a lot of unexplained world-building that you have to puzzle out as you go, you may enjoy this, although unfortunately I think you need to read at least The Stone Canal first. The ending was a bit unsatisfying, but even that includes some neat science fiction ideas. Followed by The Sky Road, although I understand it is not a straightforward sequel. Rating: 6 out of 10
 My previously mentioned C.H.I.P. repurposing has been partly successful; I ve found a use for it (which I still need to write up), but unfortunately it s too useful and the fact it s still a bit flaky has become a problem. I spent a while trying to isolate exactly what the problem is (I m still seeing occasional hard hangs with no obvious debug output in the logs or on the serial console), then realised I should just buy one of the cheap ARM SBC boards currently available.
The C.H.I.P. is based on an Allwinner R8, which is a single ARM v7 core (an A8). So it s fairly low power by today s standards and it seemed pretty much any board would probably do. I considered a Pi 2 Zero, but couldn t be bothered trying to find one in stock at a reasonable price (I ve had one on backorder from CPC since May 2022, and yes, I know other places have had them in stock since but I don t need one enough to chase and I m now mostly curious about whether it will ever ship). As the title of this post gives away, I settled on a Banana Pi BPI-M2 Zero, which is based on an Allwinner H3. That s a quad-core ARM v7 (an A7), so a bit more oompfh than the C.H.I.P. All in all it set me back 25, including a set of heatsinks that form a case around it.
I started with the vendor provided Debian SD card image, which is based on Debian 9 (stretch) and so somewhat old. I was able to dist-upgrade my way through buster and bullseye, and end up on bookworm. I then discovered the bookworm 6.1 kernel worked just fine out of the box, and even included a suitable DTB. Which got me thinking about whether I could do a completely fresh Debian install with minimal tweaking.
First thing, a boot loader. The Allwinner chips are nice in that they ll boot off SD, so I just needed a suitable u-boot image. Rather than go with the vendor image I had a look at mainline and discovered it had support! So let s build a clean image:
My previously mentioned C.H.I.P. repurposing has been partly successful; I ve found a use for it (which I still need to write up), but unfortunately it s too useful and the fact it s still a bit flaky has become a problem. I spent a while trying to isolate exactly what the problem is (I m still seeing occasional hard hangs with no obvious debug output in the logs or on the serial console), then realised I should just buy one of the cheap ARM SBC boards currently available.
The C.H.I.P. is based on an Allwinner R8, which is a single ARM v7 core (an A8). So it s fairly low power by today s standards and it seemed pretty much any board would probably do. I considered a Pi 2 Zero, but couldn t be bothered trying to find one in stock at a reasonable price (I ve had one on backorder from CPC since May 2022, and yes, I know other places have had them in stock since but I don t need one enough to chase and I m now mostly curious about whether it will ever ship). As the title of this post gives away, I settled on a Banana Pi BPI-M2 Zero, which is based on an Allwinner H3. That s a quad-core ARM v7 (an A7), so a bit more oompfh than the C.H.I.P. All in all it set me back 25, including a set of heatsinks that form a case around it.
I started with the vendor provided Debian SD card image, which is based on Debian 9 (stretch) and so somewhat old. I was able to dist-upgrade my way through buster and bullseye, and end up on bookworm. I then discovered the bookworm 6.1 kernel worked just fine out of the box, and even included a suitable DTB. Which got me thinking about whether I could do a completely fresh Debian install with minimal tweaking.
First thing, a boot loader. The Allwinner chips are nice in that they ll boot off SD, so I just needed a suitable u-boot image. Rather than go with the vendor image I had a look at mainline and discovered it had support! So let s build a clean image:
noodles@buildhost:~$ mkdir ~/BPI
noodles@buildhost:~$ cd ~/BPI
noodles@buildhost:~/BPI$ ls
noodles@buildhost:~/BPI$ git clone https://source.denx.de/u-boot/u-boot.git
Cloning into 'u-boot'...
remote: Enumerating objects: 935825, done.
remote: Counting objects: 100% (5777/5777), done.
remote: Compressing objects: 100% (1967/1967), done.
remote: Total 935825 (delta 3799), reused 5716 (delta 3769), pack-reused 930048
Receiving objects: 100% (935825/935825), 186.15 MiB 2.21 MiB/s, done.
Resolving deltas: 100% (785671/785671), done.
noodles@buildhost:~/BPI$ mkdir u-boot-build
noodles@buildhost:~/BPI$ cd u-boot
noodles@buildhost:~/BPI/u-boot$ git checkout v2023.07.02
...
HEAD is now at 83cdab8b2c Prepare v2023.07.02
noodles@buildhost:~/BPI/u-boot$ make O=../u-boot-build bananapi_m2_zero_defconfig
HOSTCC scripts/basic/fixdep
GEN Makefile
HOSTCC scripts/kconfig/conf.o
YACC scripts/kconfig/zconf.tab.c
LEX scripts/kconfig/zconf.lex.c
HOSTCC scripts/kconfig/zconf.tab.o
HOSTLD scripts/kconfig/conf
#
# configuration written to .config
#
make[1]: Leaving directory '/home/noodles/BPI/u-boot-build'
noodles@buildhost:~/BPI/u-boot$ cd ../u-boot-build/
noodles@buildhost:~/BPI/u-boot-build$ make CROSS_COMPILE=arm-linux-gnueabihf-
GEN Makefile
scripts/kconfig/conf --syncconfig Kconfig
...
LD spl/u-boot-spl
OBJCOPY spl/u-boot-spl-nodtb.bin
COPY spl/u-boot-spl.bin
SYM spl/u-boot-spl.sym
MKIMAGE spl/sunxi-spl.bin
MKIMAGE u-boot.img
COPY u-boot.dtb
MKIMAGE u-boot-dtb.img
BINMAN .binman_stamp
OFCHK .config
noodles@buildhost:~/BPI/u-boot-build$ ls -l u-boot-sunxi-with-spl.bin
-rw-r--r-- 1 noodles noodles 494900 Aug 8 08:06 u-boot-sunxi-with-spl.bin
noodles@buildhost:~/BPI$ wget https://deb.debian.org/debian/dists/bookworm/main/installer-armhf/20230607%2Bdeb12u1/images/netboot/netboot.tar.gz
...
2023-08-08 10:15:03 (34.5 MB/s) - netboot.tar.gz saved [37851404/37851404]
noodles@buildhost:~/BPI$ tar -axf netboot.tar.gz
noodles@buildhost:~/BPI$ sudo fdisk /dev/sdb
Welcome to fdisk (util-linux 2.38.1).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Command (m for help): o
Created a new DOS (MBR) disklabel with disk identifier 0x793729b3.
Command (m for help): n
Partition type
p primary (0 primary, 0 extended, 4 free)
e extended (container for logical partitions)
Select (default p):
Using default response p.
Partition number (1-4, default 1):
First sector (2048-60440575, default 2048):
Last sector, +/-sectors or +/-size K,M,G,T,P (2048-60440575, default 60440575): +500M
Created a new partition 1 of type 'Linux' and of size 500 MiB.
Command (m for help): t
Selected partition 1
Hex code or alias (type L to list all): c
Changed type of partition 'Linux' to 'W95 FAT32 (LBA)'.
Command (m for help): n
Partition type
p primary (1 primary, 0 extended, 3 free)
e extended (container for logical partitions)
Select (default p):
Using default response p.
Partition number (2-4, default 2):
First sector (1026048-60440575, default 1026048):
Last sector, +/-sectors or +/-size K,M,G,T,P (534528-60440575, default 60440575):
Created a new partition 2 of type 'Linux' and of size 28.3 GiB.
Command (m for help): w
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.
$ sudo mkfs -t vfat -n BPI-UBOOT /dev/sdb1
mkfs.fat 4.2 (2021-01-31)
noodles@buildhost:~/BPI$ sudo dd if=u-boot-build/u-boot-sunxi-with-spl.bin of=/dev/sdb bs=1024 seek=8
483+1 records in
483+1 records out
494900 bytes (495 kB, 483 KiB) copied, 0.0282234 s, 17.5 MB/s
noodles@buildhost:~/BPI$ cp -r debian-installer/ /media/noodles/BPI-UBOOT/
U-Boot SPL 2023.07.02 (Aug 08 2023 - 09:05:44 +0100)
DRAM: 512 MiB
Trying to boot from MMC1
U-Boot 2023.07.02 (Aug 08 2023 - 09:05:44 +0100) Allwinner Technology
CPU: Allwinner H3 (SUN8I 1680)
Model: Banana Pi BPI-M2-Zero
DRAM: 512 MiB
Core: 60 devices, 17 uclasses, devicetree: separate
WDT: Not starting watchdog@1c20ca0
MMC: mmc@1c0f000: 0, mmc@1c10000: 1
Loading Environment from FAT... Unable to read "uboot.env" from mmc0:1...
In: serial
Out: serial
Err: serial
Net: No ethernet found.
Hit any key to stop autoboot: 0
=> setenv dibase /debian-installer/armhf
=> fatload mmc 0:1 $ kernel_addr_r $ dibase /vmlinuz
5333504 bytes read in 225 ms (22.6 MiB/s)
=> setenv bootargs "console=ttyS0,115200n8"
=> fatload mmc 0:1 $ fdt_addr_r $ dibase /dtbs/sun8i-h2-plus-bananapi-m2-zero.dtb
25254 bytes read in 7 ms (3.4 MiB/s)
=> fdt addr $ fdt_addr_r 0x40000
Working FDT set to 43000000
=> fatload mmc 0:1 $ ramdisk_addr_r $ dibase /initrd.gz
31693887 bytes read in 1312 ms (23 MiB/s)
=> bootz $ kernel_addr_r $ ramdisk_addr_r :$ filesize $ fdt_addr_r
Kernel image @ 0x42000000 [ 0x000000 - 0x516200 ]
## Flattened Device Tree blob at 43000000
Booting using the fdt blob at 0x43000000
Working FDT set to 43000000
Loading Ramdisk to 481c6000, end 49fffc3f ... OK
Loading Device Tree to 48183000, end 481c5fff ... OK
Working FDT set to 48183000
Starting kernel ...
firmware-brcm80211 once installation completed allowed the built-in wifi to work fine.
After install you need to configure u-boot to boot without intervention. At the u-boot prompt (i.e. after hitting a key to stop autoboot):
=> setenv bootargs "console=ttyS0,115200n8 root=LABEL=BPI-ROOT ro"
=> setenv bootcmd 'ext4load mmc 0:2 $ fdt_addr_r /boot/sun8i-h2-plus-bananapi-m2-zero.dtb ; fdt addr $ fdt_addr_r 0x40000 ; ext4load mmc 0:2 $ kernel_addr_r /boot/vmlinuz ; ext4load mmc 0:2 $ ramdisk_addr_r /boot/initrd.img ; bootz $ kernel_addr_r $ ramdisk_addr_r :$ filesize $ fdt_addr_r '
=> saveenv
Saving Environment to FAT... OK
=> reset
e2label /dev/sdb2 BPI-ROOT to label / appropriately; otherwise I occasionally saw the SD card appear as mmc1 for Linux (I m guessing due to asynchronous boot order with the wifi). You should now find the device boots without intervention.
requires relation indicates that the system will not run at all or will run terribly if the requirement is not met. If the requirement is not met, it should not be installable on a system. A recommends relation means that it would be advantageous to have the recommended items, but it s not essential to run the application (it may run with a degraded experience without the recommended things though). And a supports relation means a given interface/device/control/etc. is supported by this application, but the application may work completely fine without it.
<component type="desktop-application">
<id>org.example.desktopapp</id>
<name>DesktopApp</name>
[...]
<requires>
<display_length>768</display_length>
<control>keyboard</control>
<control>pointing</control>
</requires>
[...]
</component>
requires relation, you require a small-desktop sized screen (at least 768 device-independent pixels (dp) on its smallest edge) and require a keyboard and mouse to be present / connectable. Of course, if your application needs more minimum space, adjust the requirement accordingly. Note that if the requirement is not met, your application may not be offered for installation.
Note: Device-independent / logical pixels One logical pixel (= device independent pixel) roughly corresponds to the visual angle of one pixel on a device with a pixel density of 96 dpi (for historical X11 reasons) and a distance from the observer of about 52 cm, making the physical pixel about 0.26 mm in size. When using logical pixels as unit, they might not always map to exact physical lengths as their exact size is defined by the device providing the display. They do however accurately depict the maximum amount of pixels that can be drawn in the depicted direction on the device s display space. AppStream always uses logical pixels when measuring lengths in pixels.
<component type="desktop-application">
<id>org.example.adaptive_app</id>
<name>AdaptiveApp</name>
[...]
<requires>
<display_length>360</display_length>
</requires>
<supports>
<control>keyboard</control>
<control>pointing</control>
<control>touch</control>
</supports>
[...]
</component>
<component type="desktop-application">
<id>org.example.phoneapp</id>
<name>PhoneApp</name>
[...]
<requires>
<display_length>360</display_length>
</requires>
<recommends>
<display_length compare="lt">1280</display_length>
<control>touch</control>
</recommends>
[...]
</component>
requires/recommends/suggests/supports, you may want to have a look at the relations tags described in the AppStream specification.
is-satisfied command to check if the application is compatible with the currently running operating system:
:~$ appstreamcli is-satisfied ./org.example.adaptive_app.metainfo.xml Relation check for: */*/*/org.example.adaptive_app/* Requirements: Unable to check display size: Can not read information without GUI toolkit access. Recommendations: No recommended items are set for this software. Supported:In addition to this command, AppStream 1.0 will introduce a new one as well:Physical keyboard found.
check-syscompat. This command will check the component against libappstream s mock system configurations that define a most common (whatever that is at the time) configuration for a respective chassis type.
If you pass the --details flag, you can even get an explanation why the component was considered or not considered for a specific chassis type:
:~$ appstreamcli check-syscompat --details ./org.example.phoneapp.metainfo.xml Chassis compatibility check for: */*/*/org.example.phoneapp/* Desktop: Incompatible recommends: This software recommends a display with its shortest edge being << 1280 px in size, but the display of this device has 1280 px. recommends: This software recommends a touch input device. Laptop: Incompatible recommends: This software recommends a display with its shortest edge being << 1280 px in size, but the display of this device has 1280 px. recommends: This software recommends a touch input device. Server: Incompatible requires: This software needs a display for graphical content. recommends: This software needs a display for graphical content. recommends: This software recommends a touch input device. Tablet:I hope this is helpful for people. Happy metadata writing!

sdX in the example.
$ sudo parted --script /dev/sdX mklabel msdos $ sudo parted --script /dev/sdX mkpart primary fat32 0% 100% $ sudo mkfs.vfat /dev/sdX1 $ sudo mount /dev/sdX1 /mnt/data/
debian-testing-amd64-netinst.iso here.
$ sudo kpartx -v -a debian-testing-amd64-netinst.iso # Mount the first partition on the ISO and copy its contents to the stick $ sudo mount /dev/mapper/loop0p1 /mnt/cdrom/ $ sudo rsync -av /mnt/cdrom/ /mnt/data/ $ sudo umount /mnt/cdrom # Same story with the second partition on the ISO $ sudo mount /dev/mapper/loop0p2 /mnt/cdrom/ $ sudo rsync -av /mnt/cdrom/ /mnt/data/ $ sudo umount /mnt/cdrom $ sudo kpartx -d debian-testing-amd64-netinst.iso $ sudo umount /mnt/data
/EFI/boot/bootx64.efi,
while GRUB is at /EFI/boot/grubx64.efi. This means that if you want to test a
different shim / GRUB version, you just replace the relevant files. That s it.
Take for example /usr/lib/grub/x86_64-efi/monolithic/grubx64.efi from the
package grub-efi-amd64-bin, or the signed version from
grub-efi-amd64-signed and copy them under /EFI/boot/grubx64.efi. Or perhaps
you want to try out systemd-boot? Then take
/usr/lib/systemd/boot/efi/systemd-bootx64.efi from the package
systemd-boot-efi, copy it to /EFI/boot/bootx64.efi and you re good to go.
Figuring out the right systemd-boot configuration needed to start the Installer
is left as an exercise.
/boot/grub/grub.cfg you can pass arbitrary arguments to the kernel
and the Installer itself. See the official
Installation Guide for a comprehensive list of boot parameters.
preseed/file=/cdrom/preseed.cfg and create a /preseed.cfg file on the USB
stick. As a little example:
d-i time/zone select Europe/Rome d-i passwd/root-password this-is-the-root-password d-i passwd/root-password-again this-is-the-root-password d-i passwd/user-fullname string Emanuele Rocca d-i passwd/username string ema d-i passwd/user-password password lol-haha-uh d-i passwd/user-password-again password lol-haha-uh d-i apt-setup/no_mirror boolean true d-i popularity-contest/participate boolean true tasksel tasksel/first multiselect standard
early_command and late_command. They can be
used to execute arbitrary commands and provide thus extreme flexibility! You
can go as far as replacing parts of the installer with a sed command, or maybe
wgetting an entirely different file. This is a fairly easy way to test minor
Installer patches. As an example, I ve once used this to test a patch to
grub-installer:
d-i partman/early_command string wget https://people.debian.org/~ema/grub-installer-1035085-1 -O /usr/bin/grub-installer
$ mkdir /tmp/new-initrd $ cd /tmp/new-initrd $ zstdcat /mnt/data/install.a64/initrd.gz sudo cpio -id $ vi lib/udev/rules.d/60-block.rules $ find . cpio -o -H newc zstd --stdout > /mnt/data/install.a64/initrd.gz
early_command to replace one of
the scripts used by the Installer, namely grub-installer. It turns out that
such script is installed by a udeb, so let s do things right and build a new
Installer ISO with our custom grub udeb.
dpkg-buildpackage -rfakeroot.
$ git clone https://salsa.debian.org/installer-team/debian-installer/ $ cd debian-installer/ $ sudo apt build-dep .
grub-installer udeb to the localudebs directory and create a
new netboot image:
$ cp /path/to/grub-installer_1.198_arm64.udeb build/localudebs/ $ cd build $ fakeroot make clean_netboot build_netboot
dest/netboot/mini.iso.
$ git clone https://salsa.debian.org/kernel-team/linux/ $ ./debian/bin/genorig.py https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux-stable.git
linux-stable.
debian/config/amd64/config. Don t worry about where you put it in the file,
there s a tool from https://salsa.debian.org/kernel-team/kernel-team to fix that:
$ /path/to/kernel-team/utils/kconfigeditor2/process.py .
$ export MAKEFLAGS=-j$(nproc) $ export DEB_BUILD_PROFILES='pkg.linux.nokerneldbg pkg.linux.nokerneldbginfo pkg.linux.notools nodoc' $ debian/rules orig $ debian/rules debian/control $ dpkg-buildpackage -b -nc -uc
linux_6.6~rc3-1~exp1_arm64.changes here. To
generate the udebs used by the Installer you need to first get a linux-signed
.dsc file, and then build it with sbuild in this example:
$ /path/to/kernel-team/scripts/debian-test-sign linux_6.6~rc3-1~exp1_arm64.changes $ sbuild --dist=unstable --extra-package=$PWD linux-signed-arm64_6.6~rc3+1~exp1.dsc
debian-installer/build/localudebs/ and then run fakeroot make clean_netboot
build_netboot as described in the previous section. In case you are trying to
use a different kernel version from what is currently in sid, you will have to
install the linux-image package on the system building the ISO, and change
LINUX_KERNEL_ABI in build/config/common. The linux-image dependency in
debian/control probably needs to be tweaked as well.
anna will
complain that
your new kernel cannot be found in the archive. Copy the kernel udebs you have
built onto a vfat formatted USB stick, switch to a terminal, and install them
all with udpkg:
~ # udpkg -i *.udeb
 Suresh and me celebrating Onam in Kochi.
Suresh and me celebrating Onam in Kochi.
 Four Points Hotel by Sheraton was the venue of DebConf23. Photo credits: Bilal
Four Points Hotel by Sheraton was the venue of DebConf23. Photo credits: Bilal
 Photo of the pool. Photo credits: Andreas Tille.
Photo of the pool. Photo credits: Andreas Tille.
 View from the hotel window.
View from the hotel window.
 This place served as lunch and dinner place and later as hacklab during debconf. Photo credits: Bilal
This place served as lunch and dinner place and later as hacklab during debconf. Photo credits: Bilal
 Picture of the awesome swag bag given at DebConf23. Photo credits: Ravi Dwivedi
Picture of the awesome swag bag given at DebConf23. Photo credits: Ravi Dwivedi
 My presentation photo. Photo credits: Valessio
My presentation photo. Photo credits: Valessio
 Selfie with Anisa and Kristi. Photo credits: Anisa.
Selfie with Anisa and Kristi. Photo credits: Anisa.
 Me helping with the Cheese and Wine Party.
Me helping with the Cheese and Wine Party.
 This picture was taken when there were few people in my room for the party.
This picture was taken when there were few people in my room for the party.
 Sadhya Thali: A vegetarian meal served on banana leaf. Payasam and rasam were especially yummy! Photo credits: Ravi Dwivedi.
Sadhya Thali: A vegetarian meal served on banana leaf. Payasam and rasam were especially yummy! Photo credits: Ravi Dwivedi.
 Sadhya thali being served at debconf23. Photo credits: Bilal
Sadhya thali being served at debconf23. Photo credits: Bilal
 Group photo of our daytrip. Photo credits: Radhika Jhalani
Group photo of our daytrip. Photo credits: Radhika Jhalani
 A selfie in memory of Abraham.
A selfie in memory of Abraham.
 Thanks to Niibe Yutaka (the person towards your right hand) from Japan (FSIJ), who gave me a wonderful Japanese gift during debconf23: A folder to keep pages with ancient Japanese manga characters printed on it. I realized I immediately needed that :)
Thanks to Niibe Yutaka (the person towards your right hand) from Japan (FSIJ), who gave me a wonderful Japanese gift during debconf23: A folder to keep pages with ancient Japanese manga characters printed on it. I realized I immediately needed that :)
 This is the Japanese gift I received.
This is the Japanese gift I received.
 Click to enlarge
Click to enlarge
 Bits from the DPL. Photo credits: Bilal
Bits from the DPL. Photo credits: Bilal
 Kristi on GNOME community. Photo credits: Ravi Dwivedi.
Kristi on GNOME community. Photo credits: Ravi Dwivedi.
 Abhas' talk on home automation. Photo credits: Ravi Dwivedi.
Abhas' talk on home automation. Photo credits: Ravi Dwivedi.
 I was roaming around with a QR code on my T-shirt for downloading Prav.
I was roaming around with a QR code on my T-shirt for downloading Prav.
 Me in mundu. Picture credits: Abhijith PA
Me in mundu. Picture credits: Abhijith PA
 From left: Nilesh, Saswata, me, Sahil. Photo credits: Sahil.
From left: Nilesh, Saswata, me, Sahil. Photo credits: Sahil.
 Ruchika (taking the selfie) and from left to right: Yash, Joost (Netherlands), me, Rhonda
Ruchika (taking the selfie) and from left to right: Yash, Joost (Netherlands), me, Rhonda
 Joost and me going to Delhi. Photo credits: Ravi.
Joost and me going to Delhi. Photo credits: Ravi.
 I very, very nearly didn t make it to DebConf this year, I had a bad cold/flu for a few days before I left, and after a negative covid-19 test just minutes before my flight, I decided to take the plunge and travel.
This is just everything in chronological order, more or less, it s the only way I could write it.
I very, very nearly didn t make it to DebConf this year, I had a bad cold/flu for a few days before I left, and after a negative covid-19 test just minutes before my flight, I decided to take the plunge and travel.
This is just everything in chronological order, more or less, it s the only way I could write it.










 If you got one of these Cheese & Wine bags from DebConf, that s from the South African local group!
If you got one of these Cheese & Wine bags from DebConf, that s from the South African local group! Some hopefully harmless soldering.
Some hopefully harmless soldering.



 (I wrote this up for an internal work post, but I figure it s worth sharing more publicly too.)
I spent last week at DebConf23, this years instance of the annual Debian conference, which was held in Kochi, India. As usual, DebConf provides a good reason to see a new part of the world; I ve been going since 2004 (Porto Alegre, Brazil), and while I ve missed a few (Mexico, Bosnia, and Switzerland) I ve still managed to make it to instances on 5 continents.
This has absolutely nothing to do with work, so I went on my own time + dime, but I figured a brief write-up might prove of interest. I first installed Debian back in 1999 as a machine that was being co-located to operate as a web server / email host. I was attracted by the promise of easy online upgrades (or, at least, upgrades that could be performed without the need to be physically present at the machine, even if they naturally required a reboot at some point). It has mostly delivered on this over the years, and I ve never found a compelling reason to move away. I became a Debian Developer in 2000. As a massively distributed volunteer project DebConf provides an opportunity to find out what s happening in other areas of the project, catch up with team mates, and generally feel more involved and energised to work on Debian stuff. Also, by this point in time, a lot of Debian folk are good friends and it s always nice to catch up with them.
On that point, I felt that this year the hallway track was not quite the same as usual. For a number of reasons (COVID, climate change, travel time, we re all getting older) I think fewer core teams are achieving critical mass at DebConf - I was the only member physically present from 2 teams I m involved in, and I d have appreciated the opportunity to sit down with both of them for some in-person discussions. It also means it s harder to use DebConf as a venue for advancing major changes; previously having all the decision makers in the same space for a week has meant it s possible to iron out the major discussion points, smoothing remote implementation after the conference. I m told the mini DebConfs are where it s at for these sorts of meetings now, so perhaps I ll try to attend at least one of those next year.
Of course, I also went to a bunch of talks. I have differing levels of comment about each of them, but I ve written up some brief notes below about the ones I remember something about. The comment was made that we perhaps had a lower level of deep technical talks, which is perhaps true but I still think there were a number of high level technical talks that served to pique ones interest about the topic.
Finally, this DebConf was the first I m aware of that was accompanied by tragedy; as part of the day trip Abraham Raji, a project member and member of the local team, was involved in a fatal accident.
(I wrote this up for an internal work post, but I figure it s worth sharing more publicly too.)
I spent last week at DebConf23, this years instance of the annual Debian conference, which was held in Kochi, India. As usual, DebConf provides a good reason to see a new part of the world; I ve been going since 2004 (Porto Alegre, Brazil), and while I ve missed a few (Mexico, Bosnia, and Switzerland) I ve still managed to make it to instances on 5 continents.
This has absolutely nothing to do with work, so I went on my own time + dime, but I figured a brief write-up might prove of interest. I first installed Debian back in 1999 as a machine that was being co-located to operate as a web server / email host. I was attracted by the promise of easy online upgrades (or, at least, upgrades that could be performed without the need to be physically present at the machine, even if they naturally required a reboot at some point). It has mostly delivered on this over the years, and I ve never found a compelling reason to move away. I became a Debian Developer in 2000. As a massively distributed volunteer project DebConf provides an opportunity to find out what s happening in other areas of the project, catch up with team mates, and generally feel more involved and energised to work on Debian stuff. Also, by this point in time, a lot of Debian folk are good friends and it s always nice to catch up with them.
On that point, I felt that this year the hallway track was not quite the same as usual. For a number of reasons (COVID, climate change, travel time, we re all getting older) I think fewer core teams are achieving critical mass at DebConf - I was the only member physically present from 2 teams I m involved in, and I d have appreciated the opportunity to sit down with both of them for some in-person discussions. It also means it s harder to use DebConf as a venue for advancing major changes; previously having all the decision makers in the same space for a week has meant it s possible to iron out the major discussion points, smoothing remote implementation after the conference. I m told the mini DebConfs are where it s at for these sorts of meetings now, so perhaps I ll try to attend at least one of those next year.
Of course, I also went to a bunch of talks. I have differing levels of comment about each of them, but I ve written up some brief notes below about the ones I remember something about. The comment was made that we perhaps had a lower level of deep technical talks, which is perhaps true but I still think there were a number of high level technical talks that served to pique ones interest about the topic.
Finally, this DebConf was the first I m aware of that was accompanied by tragedy; as part of the day trip Abraham Raji, a project member and member of the local team, was involved in a fatal accident.
/etc/network/interfaces is a fairly basic (if powerful) mechanism for configuring network interfaces. NetworkManager is a better bet for dynamic hosts (i.e. clients), and systemd-network seems to be a good choice for servers (I m gradually moving machines over to it). Netplan tries to provide a unified mechanism for configuring both with a single configuration language. A noble aim, but I don t see a lot of benefit for anything I use - my NetworkManager hosts are highly dynamic (so no need to push shared config) and systemd-network (or /etc/network/interfaces) works just fine on the other hosts. I m told Netplan has more use with more complicated setups, e.g. when OpenVSwitch is involved.
.deb and chisel it into smaller components, which then helps separate out dependencies rather than pulling in as much as the original .deb would. This was touted as being useful, in particular, for building targeted containers. Definitely appealing over custom built userspaces for containers, but in an ideal world I think we d want the information in the main packaging and it becomes a lot of work.


-# LANGUAGE OverloadedStrings #-
import Wasmjsbridge
foreign export ccall hello :: IO ()
hello :: IO ()
hello = do
alert <- get_js_object_method "window" "alert"
call_js_function_ByteString_Void alert "hello, world!"
foreign import ccall unsafe "call_js_function_string_void"
_call_js_function_string_void :: Int -> CString -> Int -> IO ()
call_js_function_ByteString_Void :: JSFunction -> B.ByteString -> IO ()
call_js_function_ByteString_Void (JSFunction n) b =
BU.unsafeUseAsCStringLen b $ \(buf, len) ->
_call_js_function_string_void n buf len
void _call_js_function_string_void(uint32_t fn, uint8_t *buf, uint32_t len) __attribute__((
__import_module__("wasmjsbridge"),
__import_name__("call_js_function_string_void")
));
void call_js_function_string_void(uint32_t fn, uint8_t *buf, uint32_t len)
_call_js_function_string_void(fn, buf, len);
call_js_function_string_void(n, b, sz)
const fn = globalThis.wasmjsbridge_functionmap.get(n);
const buffer = globalThis.wasmjsbridge_exports.memory.buffer;
fn(decoder.decode(new Uint8Array(buffer, b, sz)));
,
document.alert. Why not
pass a ByteString with that through the FFI? Well, you could. But then
it would have to eval it. That would make running WASM in the browser be
evaling Javascript every time it calls a function. That does not seem like a
good idea if the goal is speed. GHC's
javascript backend
does use Javascript FFI snippets like that, but there they get pasted into the generated
Javascript hairball, so no eval is needed.
So my code has things like get_js_object_method that look up things like
Javascript functions and generate identifiers. It also has this:
call_js_function_ByteString_Object :: JSFunction -> B.ByteString -> IO JSObject
document.getElementById
that return a javascript object:
getElementById <- get_js_object_method (JSObjectName "document") "getElementById"
canvas <- call_js_function_ByteString_Object getElementById "myCanvas"
get_js_object_method. It generates a
Javascript function that will be used to call the desired method of the object,
and allocates an identifier for it, and returns that to the caller.
get_js_objectname_method(ob, osz, nb, nsz)
const buffer = globalThis.wasmjsbridge_exports.memory.buffer;
const objname = decoder.decode(new Uint8Array(buffer, ob, osz));
const funcname = decoder.decode(new Uint8Array(buffer, nb, nsz));
const func = function (...args) return globalThis[objname][funcname](...args) ;
const n = globalThis.wasmjsbridge_counter + 1;
globalThis.wasmjsbridge_counter = n;
globalThis.wasmjsbridge_functionmap.set(n, func);
return n;
,
 TPMs contain a set of registers ("Platform Configuration Registers", or PCRs) that are used to track what a system boots. Each time a new event is measured, a cryptographic hash representing that event is passed to the TPM. The TPM appends that hash to the existing value in the PCR, hashes that, and stores the final result in the PCR. This means that while the PCR's value depends on the precise sequence and value of the hashes presented to it, the PCR value alone doesn't tell you what those individual events were. Different PCRs are used to store different event types, but there are still more events than there are PCRs so we can't avoid this problem by simply storing each event separately. Another minor release, now at 0.2.4, of our RcppRedis
package arrived on CRAN
yesterday. RcppRedis
is one of several packages connecting R to the fabulous Redis in-memory datastructure store (and
much more). RcppRedis
does not pretend to be feature complete, but it may do some things
faster than the other interfaces, and also offers an optional coupling
with MessagePack binary
(de)serialization via RcppMsgPack. The
package has carried production loads on a trading floor for several
years. It also supports pub/sub dissemination of streaming market data
as per this
earlier example.
This update is (just like the previous one) fairly mechanical. CRAN noticed a shortcoming of the
default per-package help page in a number of packages, in our case it
was matter of adding one line for a missing alias to the Rd file. We
also demoted the mention of the suggested (but retired) rredis package to a mere
mention in the DESCRIPTION file as a formal Suggests: entry, even with
an added Additional_repositories, create a NOTE. Life is simpler without
those,
The detailed changes list follows.
TPMs contain a set of registers ("Platform Configuration Registers", or PCRs) that are used to track what a system boots. Each time a new event is measured, a cryptographic hash representing that event is passed to the TPM. The TPM appends that hash to the existing value in the PCR, hashes that, and stores the final result in the PCR. This means that while the PCR's value depends on the precise sequence and value of the hashes presented to it, the PCR value alone doesn't tell you what those individual events were. Different PCRs are used to store different event types, but there are still more events than there are PCRs so we can't avoid this problem by simply storing each event separately. Another minor release, now at 0.2.4, of our RcppRedis
package arrived on CRAN
yesterday. RcppRedis
is one of several packages connecting R to the fabulous Redis in-memory datastructure store (and
much more). RcppRedis
does not pretend to be feature complete, but it may do some things
faster than the other interfaces, and also offers an optional coupling
with MessagePack binary
(de)serialization via RcppMsgPack. The
package has carried production loads on a trading floor for several
years. It also supports pub/sub dissemination of streaming market data
as per this
earlier example.
This update is (just like the previous one) fairly mechanical. CRAN noticed a shortcoming of the
default per-package help page in a number of packages, in our case it
was matter of adding one line for a missing alias to the Rd file. We
also demoted the mention of the suggested (but retired) rredis package to a mere
mention in the DESCRIPTION file as a formal Suggests: entry, even with
an added Additional_repositories, create a NOTE. Life is simpler without
those,
The detailed changes list follows.
Courtesy of my CRANberries, there is also a diffstat report for this this release. More information is on the RcppRedis page. If you like this or other open-source work I do, you can sponsor me at GitHub.Changes in version 0.2.4 (2023-08-19)
- Add missing alias for RcppRedis-package to
rhiredis.Rd.- Remove Suggests: rredis which triggers a NOTE nag as it is only on an Additional_repositories .
This post by Dirk Eddelbuettel originated on his Thinking inside the box blog. Please report excessive re-aggregation in third-party for-profit settings.
 I've been maintaining a number of Perl software packages recently.
There's SReview,
my video review and transcoding system of which I split off
Media::Convert a while
back; and as of about a year ago, I've also added
PtLink, an RSS aggregator
(with future plans for more than just that).
All these come with extensive test suites which can help me ensure that
things continue to work properly when I play with things; and all of
these are hosted on salsa.debian.org, Debian's gitlab instance. Since
we're there anyway, I configured GitLab CI/CD to run a full test suite
of all the software, so that I can't forget, and also so that I know
sooner rather than later when things start breaking.
GitLab has extensive support for various test-related reports, and while
it took a while to be able to enable all of them, I'm happy to report
that today, my perl test suites generate all three possible reports.
They are:
I've been maintaining a number of Perl software packages recently.
There's SReview,
my video review and transcoding system of which I split off
Media::Convert a while
back; and as of about a year ago, I've also added
PtLink, an RSS aggregator
(with future plans for more than just that).
All these come with extensive test suites which can help me ensure that
things continue to work properly when I play with things; and all of
these are hosted on salsa.debian.org, Debian's gitlab instance. Since
we're there anyway, I configured GitLab CI/CD to run a full test suite
of all the software, so that I can't forget, and also so that I know
sooner rather than later when things start breaking.
GitLab has extensive support for various test-related reports, and while
it took a while to be able to enable all of them, I'm happy to report
that today, my perl test suites generate all three possible reports.
They are:
coverage regex, which captures the total reported coverage for
all modules of the software; it will show the test coverage on the
right-hand side of the job page (as in this
example), and
it will show what the delta in that number is in merge request
summaries (as in this
exampletest:
stage: test
image: perl:latest
coverage: '/^Total.* (\d+.\d+)$/'
before_script:
- cpanm ExtUtils::Depends Devel::Cover TAP::Harness::JUnit Devel::Cover::Report::Cobertura
- cpanm --notest --installdeps .
- perl Makefile.PL
script:
- cover -delete
- HARNESS_PERL_SWITCHES='-MDevel::Cover' prove -v -l -s --harness TAP::Harness::JUnit
- cover
- cover -report cobertura
artifacts:
paths:
- cover_db
reports:
junit: junit_output.xml
coverage_report:
path: cover_db/cobertura.xml
coverage_format: cobertura
test; we start it in the test
stage, and we run it in the perl:latest docker image. Nothing
spectacular here.
The coverage line contains a regular expression. This is applied by
GitLab to the output of the job; if it matches, then the first bracket
match is extracted, and whatever that contains is assumed to contain the
code coverage percentage for the code; it will be reported as such in
the GitLab UI for the job that was ran, and graphs may be drawn to show
how the coverage changes over time. Additionally, merge requests will
show the delta in the code coverage, which may help deciding whether to
accept a merge request. This regular expression will match on a line of
that the cover program will generate on standard output.
The before_script section installs various perl modules we'll need
later on. First, we intall
ExtUtils::Depends. My code
uses
ExtUtils::MakeMaker,
which ExtUtils::Depends depends on (no pun intended); obviously, if your
perl code doesn't use that, then you don't need to install it. The next
three modules -- Devel::Cover,
TAP::Harness::JUnit and
Devel::Cover::Report::Cobertura
are necessary for the reports, and you should include them if you want
to copy what I'm doing.
Next, we install declared dependencies, which is probably a good idea
for you as well, and then we run perl Makefile.PL, which will generate
the Makefile. If you don't use ExtUtils::MakeMaker, update that part to
do what your build system uses. That should be fairly straightforward.
You'll notice that we don't actually use the Makefile. This is because
we only want to run the test suite, which in our case (since these are
PurePerl modules) doesn't require us to build the software first. One
might consider that this makes the call of perl Makefile.PL useless,
but I think it's a useful test regardless; if that fails, then obviously
we did something wrong and shouldn't even try to go further.
The actual tests are run inside a script snippet, as is usual for
GitLab. However we do a bit more than you would normally expect; this is
required for the reports that we want to generate. Let's unpack what we
do there:
cover -delete
HARNESS_PERL_SWITCHES='-MDevel::Cover'
cover_db directory, and allows you to generate all kinds of
reports on the code coverage later (but we don't do that here, yet).
prove -v -l -s
verbose output, shuffling (aka,
randomizing) the test suite, and adding the lib directory to perl's
include path. This works for us, again, because we don't actually need
to compile anything; if you do, then -b (for blib) may be required.
ExtUtils::MakeMaker creates a test target in its Makefile, and usually
this is how you invoke the test suite. However, it's not the only way to
do so, and indeed if you want to generate a JUnit XML report then you
can't do that. Instead, in that case, you need to use the prove, so
that you can tell it to load the TAP::Harness::JUnit module by way of
the --harness option, which will then generate the JUnit XML report.
By default, the JUnit XML report is generated in a file
junit_output.xml. It's possible to customize the filename for this
report, but GitLab doesn't care and neither do I, so I don't. Uploading
the JUnit XML format tells GitLab which tests were run and
Finally, we invoke the cover script twice to generate two coverage
reports; once we generate the default report (which generates HTML files
with detailed information on all the code that was triggered in your
test suite), and once with the -report cobertura parameter, which
generates the cobertura XML format.
Once we've generated all our reports, we then need to upload them to
GitLab in the right way. The native perl report, which is in the
cover_db directory, is uploaded as a regular job artifact, which we
can then look at through a web browser, and the two XML reports are
uploaded in the correct way for their respective formats.
All in all, I find that doing this makes it easier to understand how my
code is tested, and why things go wrong when they do.


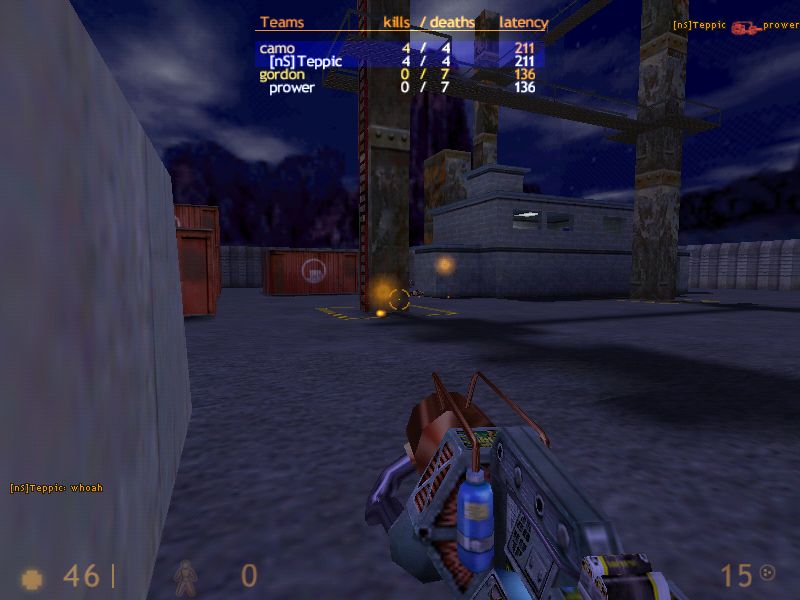 Lots of mid-90s games had very boxy floors
Lots of mid-90s games had very boxy floors
](https://jmtd.net/log/zarchscape/carpet_90s.jpg) Terrain generation, 90s-style. From this article
Terrain generation, 90s-style. From this article

Next.
{kind=link}